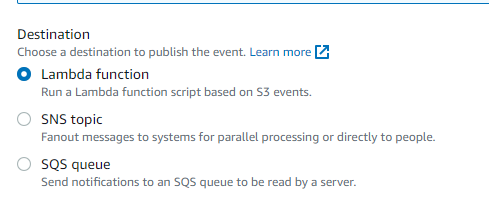
One of the features of S3 is the ability to send event notifications when specific actions occur in your bucket. S3 event notifications triggers a variety of actions in response to particular events, such as:
- Sending a notification to SQS queue to be read by a server, when a object is created or deleted.
- Sending a message to an Amazon Simple Notification Service (SNS) topic when an object is created or deleted.
- Invoking an AWS Lambda function when an object is created or deleted.
You might want to use S3 event notifications in the following scenarios or specific business use case:
- Automating data processing workflows: You can use S3 event notifications to trigger a Lambda function to process data when it is added to a bucket. This can be useful for automating data pipelines, data transformations, or data analysis tasks.
- Monitoring bucket activity: You can use S3 event notifications to send an email or an SNS message when specific actions occur in a bucket, such as when an object “is deleted” or access to an object “is denied.” This can help you track your bucket’s activity and identify any potential issues.
- Syncing data between buckets: You can use S3 event notifications to automatically copy objects between buckets in different regions or accounts when certain events occur. This can be beneficial for maintaining redundant copies of data for disaster recovery or replicating data between environments.
- Automating image or video processing: You can use S3 event notifications to trigger a Lambda function to process images or videos when they are added to a bucket. This can be useful for resizing images, creating thumbnails, or transcoding video files.
Overall, S3 event notifications are a valuable tool for automating workflows and monitoring activity in your S3 buckets. They can help you build scalable and reliable systems that process and store large amounts of data.
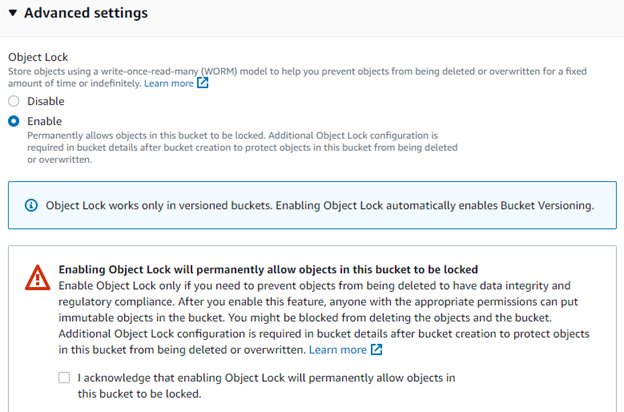
Amazon S3 Object Lock is a feature of Amazon S3 that lets you store objects using a write-once-read-many (WORM) model. You can use WORM protection for scenarios where it is imperative that data is not changed or deleted after it has been written.
“Object Lock” is used in various scenarios where it is essential to prevent accidental or unauthorized deletion or overwriting of objects, such as in regulated industries or when storing critical business data.
Some specific use cases for Object Lock include:
- Compliance: Object Lock can be used to meet regulatory requirements for data retention, such as the SEC Rule 17a-4 and FINRA Rule 4511, which require certain financial records to be kept for a specific period.
- Data archiving: Object Lock can be applied to store data that needs to be kept for long periods, such as data required for legal or compliance purposes.
- Data protection: Object Lock can protect critical data from being deleted or overwritten, such as backups or disaster recovery data.
You can enable Object Lock on individual objects or on a bucket, which will apply Object Lock to all objects stored in the bucket. As of now, you can enable Object Lock during the creation time of the bucket only.